Arquitectura Empresarial de Datos con Data Lake + Google Cloud Platform – 2020/04

El 30 de Abril de 2020 tuve el placer de participar como orador en un evento online de Algeiba realizado junto a Google, donde revisamos los aspectos más importantes de una arquitectura empresarial de datos basada en Data Lake.
En esta publicación te compartiremos la presentación, materiales vistos, e info extendida de lo que fue la jornada. A todas las personas que estuvieron online: ¡gracias por participar!
Contenidos
¿Qué es Data Lake?
Los Data Lakes son colecciones de datos sin procesar, tanto estructurados como no estructurados, que han sido alojados en un lugar de almacenamiento para diversos fines. Esto que parece una definición tan simple y obvia, tiene características específicas:
- Datos sin procesar: esto significa que los datos no tienen transformación antes de ser alojados en este repositorio. Contrariamente al concepto de “ETL” (extract – transform – load) donde se asume una transformación de datos (típicamente visto en un datawarehouse), en el caso de los Data Lakes los datos no se transforman.
- Estructuras de datos variadas: esto significa que los datos que contiene el Data Lake pueden ser estructurados, semi estructurados, no estructurados, o (lo más común) es que sean mixtos (es decir, que existan algunos estructurados, semi estructurados y otros no estructurados en el mismo repositorio). Para ser claros: puedo tener en un Data Lake datos de una base de datos relacional, como también datos de fuentes de datos documentales que no tienen una estructura válida desde la analítica clásica. Ejemplos de datos no estructurados son: archivos varios (pdf, word, etc), publicaciones sociales, etc. Ejemplos de datos semi estructurados son archivos de tipo JSON.
- No se vincula a ninguna tecnología de procesamiento: esto quiere decir que el Data Lake es un sello definitivo de separación entre cómputo y almacenamiento de datos. De hecho, veremos que pueden existir varias tecnologías de procesamiento que dieron origen a los datos, o que luego sean utilizadas para análisis.
- Son multipropósito: esto quiere decir que los datos presentes en un Data Lake luego se podrán utilizar para muchos propósitos diferentes, como por ejemplo análisis hasta ciencia de datos y machine learning.
¿Por qué un Data Lake?
La pregunta que suelen hacernos es la siguiente:
“Si yo estoy cómodo con un Data Warehouse y no tengo problemas: ¿por qué un Data Lake?”
– Varios profesionales de IT “anónimos” 🙂
Bien, en este punto no vamos a negar que soluciones de tipo “Data Warehouse” muchas veces cumplen satisfactoriamente con su propósito. Ahora bien, analicemos algunos casos en los que podría no ser tan así:
- Debo analizar e incluir, en mi data warehouse, datos de redes sociales, dispositivos IoT y hasta documentos que (por su naturaleza) no son estructurados: una aproximación clásica sería que, antes de incluirlos en el data warehouse, debo pre-procesarlos para “adaptarlos” a un esquema definido de datos.
- Mis origenes de datos son cambiantes, es decir que los equipos de desarrollo de software o la solución de software con la que cuento, tiene incorporado fuentes de datos semi-estructurados (MongoDB, CosmosDB, DocumentDB, etc). En dicho caso, al igual que el punto anterior, debería de pre-procesarlos para “adaptarlos” a mi esquema definido de datos, o cambiar mi esquema definido de datos para incorporar estos nuevos.
- Debo incluir más datos, o datos faltantes, a mi data warehouse, por diversos motivos. Entre ellos: tomé una decisión en el pasado (sobre cantidad y calidad de datos alojada en mi almacén) que ahora necesito corregirla por necesidades de negocio.
Tener presente cualquiera de estos tres puntos que pusimos de ejemplo, nos da indicios que quizás debamos pensar en un Data Lake y ya no tanto en un Data Warehouse (o al menos, en esto último solo). ¿Por qué? Por los siguientes puntos:
- Escalabilidad y Precio: los datos pueden ser alojados y procesados luego sin afectar las cargas productivas, sin preocuparme por el escalamiento y sin ocuparme por el precio (que suele ser muy bajo).
- Menor esfuerzo inicial: no debo ocuparme de diseñar esquemas de datos que “se adapten” a mi almacén. Simplemente guardo los datos, sin pre procesamiento. Luego me ocuparé de generar los vínculos y esquemas de datos que necesite, en el momento de la lectura y sólo en el momento necesario. Si en un futuro me doy cuenta que necesito vincular más datos, simplemente ya los tengo allí, y “juego” con nuevos esquemas en una capa posterior.
- Casos de Uso variados: diferentes públicos de usuarios pueden acceder a la información, en el mismo momento, con mínimo esfuerzo. Si necesito segurizar y diferenciar el acceso a los datos, lo haré por una capa semántica mantenida por código. No por datos diferenciados.
Solución Data Lake con Google
Te mostramos una arquitectura de referencia que facilita la creacion, mantenimiento y explotación de un Data Lake con el stack tecnológico de Google:
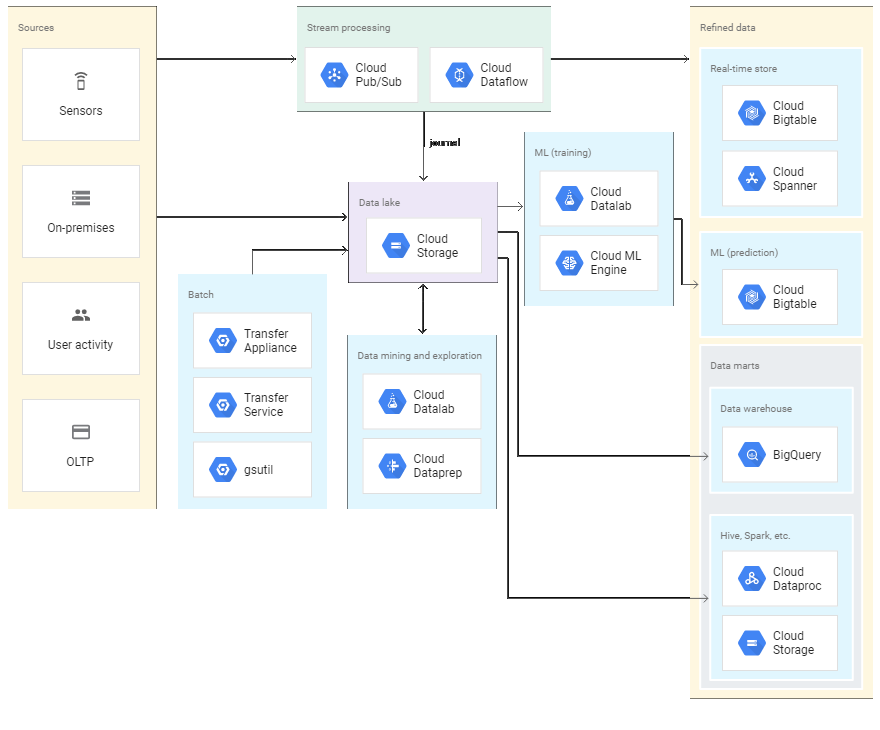
Como podrán observar, existe una variedad de servicios existentes en Google Cloud Platform (GCP) que podemos aprovechar, y de alguna manera aceleran la construcción de nuestra solución final. Justamente, durante nuestra charla, vimos varios de ellos.
Presentación brindada en la Charla
Te compartimos la presentación compartida durante nuestra sesión:
Video (extra) sobre Data Lake
Como material extra, te dejamos una excelente charla del Cloud Next 2018 donde James Malone (parte del equipo de Google Cloud) compartió las oportunidades que nos brindan las arquitecturas Data Lake en el mundo real:
Fotos del Evento
En plena pandemia del COVID-19, y trabajando desde casa en Buenos Aires, te comparto las siguientes “fotos del evento”:


A todos los que se conectaron y participaron de la sesión: ¡muchas gracias!
Professor. Techie. Ice cream fan (dulce de leche). My favorite phrase: "Todos los días pueden no ser buenos ... pero hay algo bueno en todos los días". Currently I´m Engineering Manager at MODO (https://modo.com.ar), the payment solution that allows you to connect your money and your world to simplify everyday life. Modo is a payment solution in which you can send, order and pay from your mobile device in the safest, most practical and convenient way. I enjoy a lot of educational, technological talks and a good beer. If you want to talk, write me to pablodiloreto@hotmail.com.